What is Alpaca?¶
Provenance is a term that refers to a description of all details that have led to the creation of a certain object. In the context of processing data on a computer, this involves recording the individual steps and the environment that were used to arrive at the processed data. Where such data processing is performed by a Python script, this may involve information such as the Python environment, the script and script version used, and any input files. While this information will suffice to ensure reproducibility of the data processing, it is not possible to tell what was done to the input data without the need to study the script, and more often than not, observe the execution of the script in a debugger to track the individual variables.
Automated Lightweight Provenance Capture (Alpaca) is a toolbox to easily capture and serialize more detailed provenance information when running Python scripts. To this end, Alpaca generates an additional file with the provenance information as metadata to accompany the output files of a script. For example, considering a script that reads a data file and produces a figure as an image output file, Alpaca will generate an additional file containing the provenance of the image in terms of the data flow and functions used by the script to generate the figure.
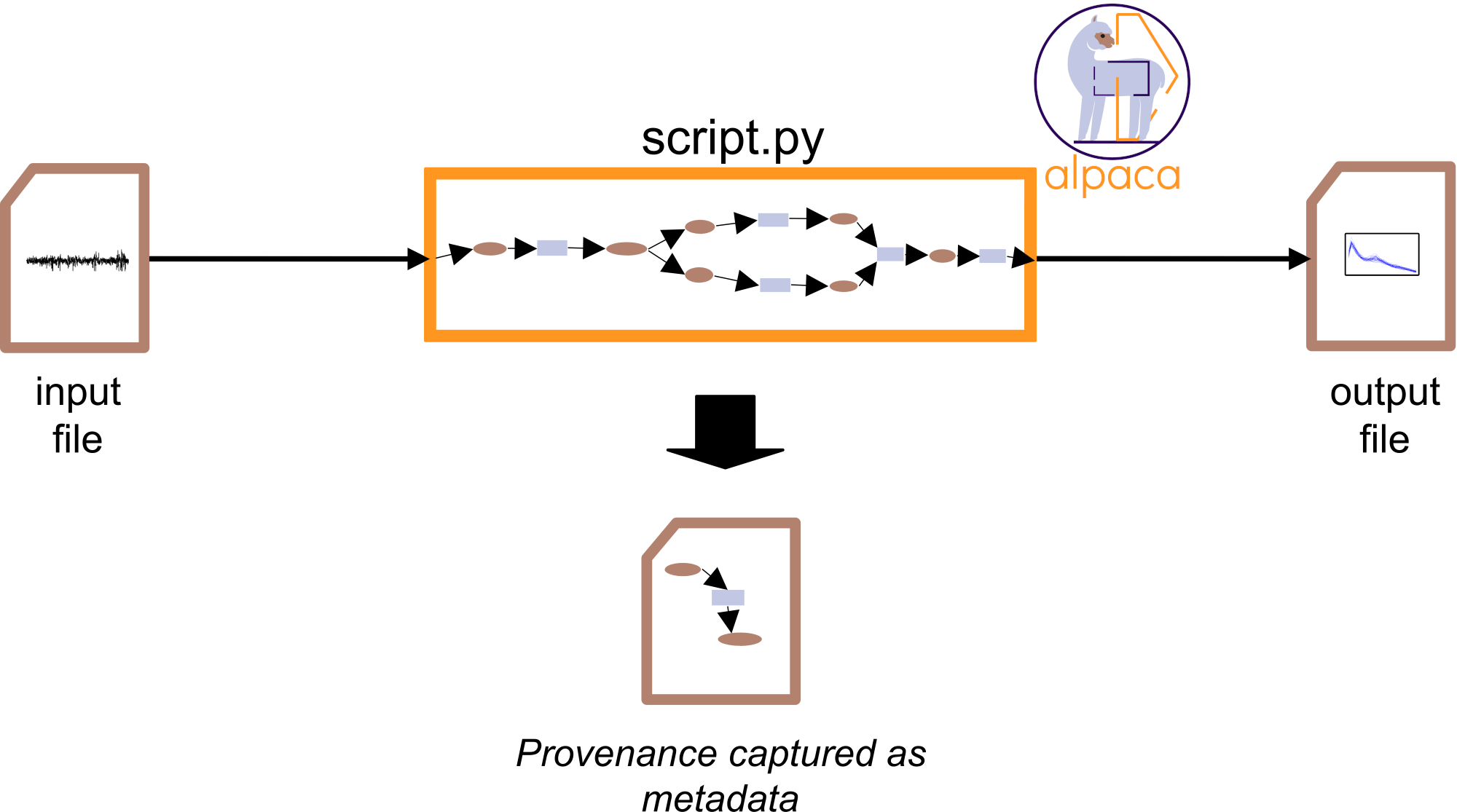
How Alpaca captures provenance?¶
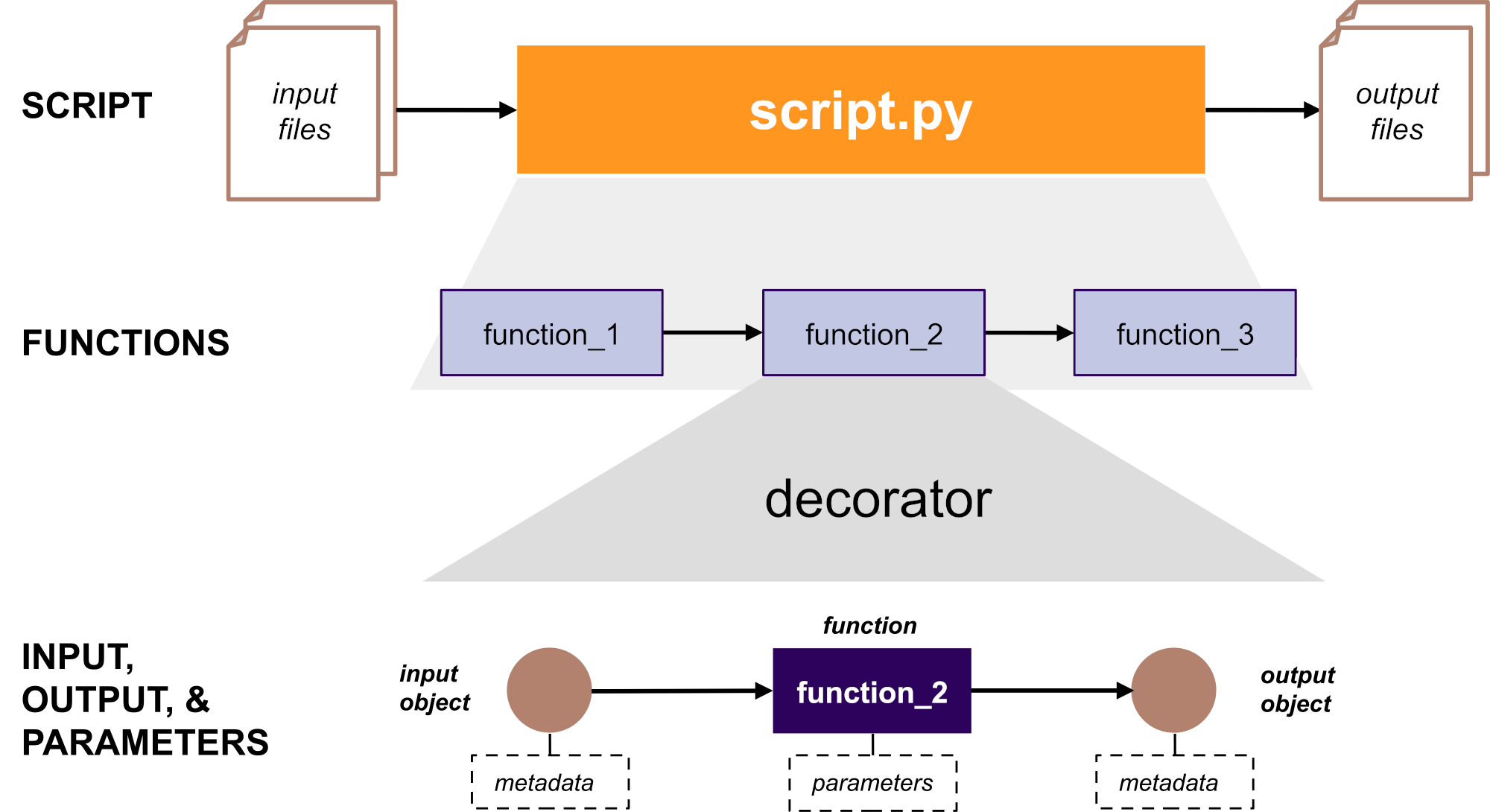
The design of Alpaca is based on the notion that a Python script is composed of a series of functions, executed in sequence. The function may take some data as input, and produce output based on a transformation of that data or generate new data. Finally, the functions may be controlled by parameters that modify their behavior and affect the generation of the output.
Therefore, we define the following concepts with respect to a function used in the Python script:
input: a file or Python object that provides data for the function. It is one of the function arguments (positional or keyword);
output: a file or Python object generated by a function. Can be a return value of the function or one of the function arguments;
parameter: any other function argument (positional or keyword) that is neither an input nor an output;
metadata: additional information contained in the input/output. These can be information accessible by attributes of the Python objects (i.e., accessed by the dot . after the object name, such as data.shape) or files (e.g., the file path).
When using Alpaca, a provenance track that contains the sequence of functions called in the script is built, and the relationships between inputs/outputs are captured together with the relevant parameters used in each function call. Additionally, certain properties (metadata) of the inputs/outputs are captured to help understanding and interpreting the provenance.
The capture is accomplished by a function decorator that it is used to identify the inputs, outputs, and parameters at runtime. It also analyzes attributes and other object relationships relevant to build the provenance track. The user must apply the decorator to each function in the Python script to allow tracking, or resort to libraries that offer their functionality with the corresponding decorators already in place.
Serialization of provenance information as metadata¶
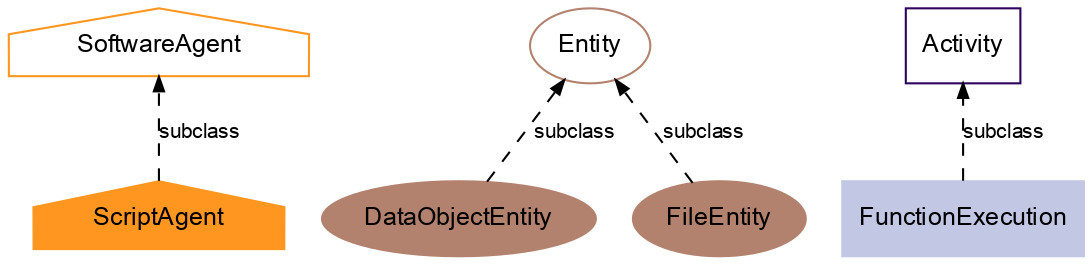
Ultimately, the captured provenance information can be serialized as a text file using RDF according to the provenance data model defined by the W3C PROV standard. For that, the base PROV-O ontology was extended to incorporate Alpaca elements. The following classes are defined:
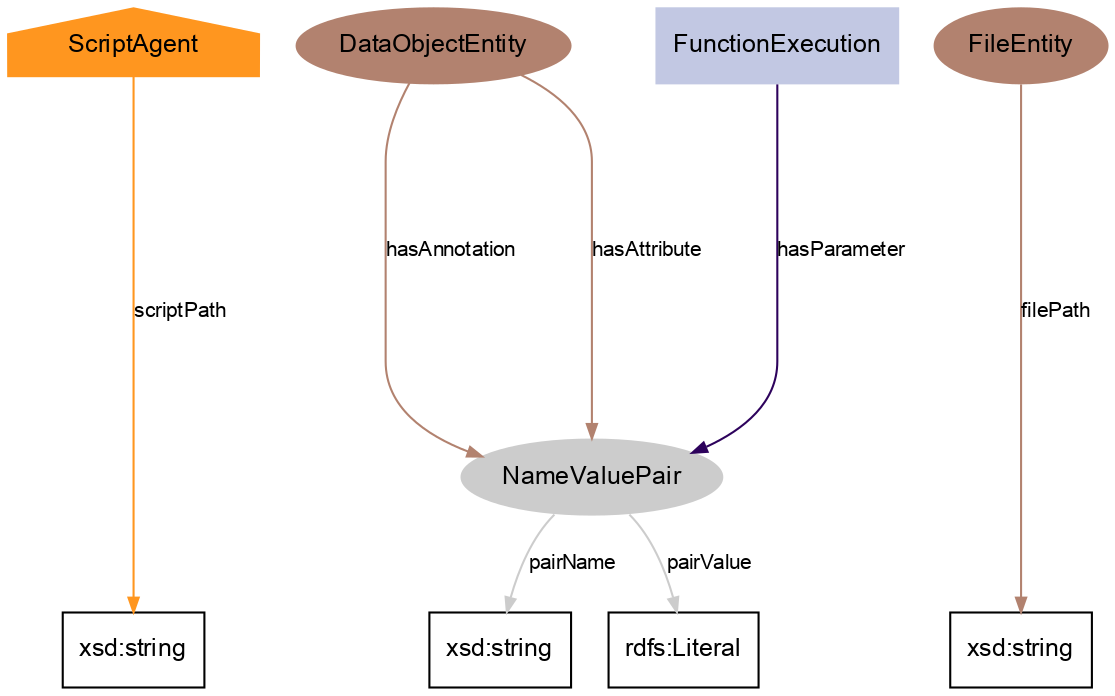
DataObjectEntity: any Python object that was input to/output from a function;
FileEntity: any file that was input to/output from a function;
FunctionExecution: every single function call executed by the script;
ScriptAgent: represents the script whose execution the provenance information was captured from.
The figure below shows the relationship of Alpaca classes (filled shapes) to the base PROV-O classes (unfilled shapes):
For these classes, the usual PROV-O relationships describing provenance apply:
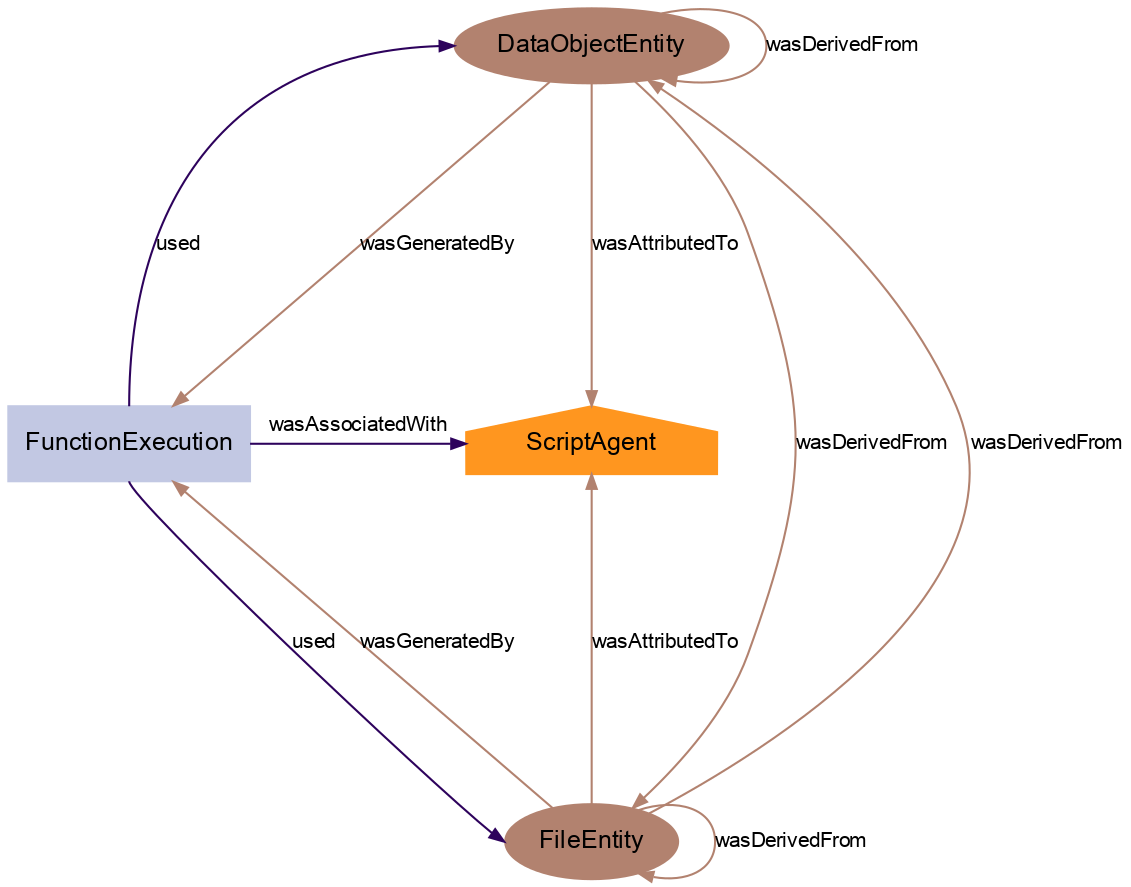
Finally, extended properties in the Alpaca ontology were defined, to store relevant provenance information:
hasParameter: describes a function parameter in the FunctionExecution;
hasAttribute: describes a metadata value in the DataObjectEntity;
hasAnnotation: describes one annotation metadata in the DataObjectEntity. Annotations are special metadata stored as key/value pairs stored in dictionaries that are part of the object, such as the annotations of Neo objects.
These extended properties are stored as special values (NameValuePair class), where pairName is a string describing the parameter, attribute, or annotation name, and pairValue contains the actual value. This allows serialization of specific names without the risk of breaking RDF syntax.
Finally, each object is identified with an URI, based on its type and contents, that is automatically generated.